MARS Lab
End-to-end Transformer-Based Sensor Fusion in Autonomous Driving
|
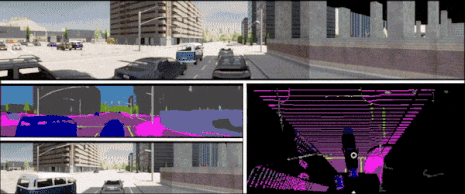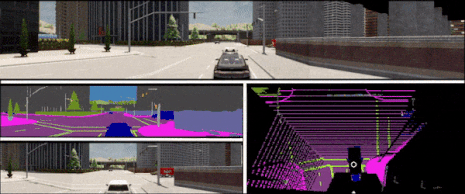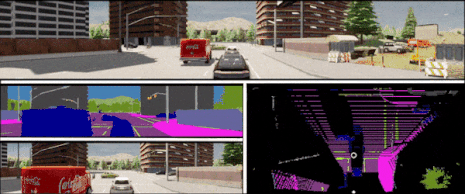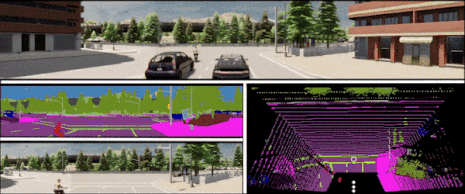
In the context of end-to-end autonomous driving, current sensor fusion techniques for imitation learning are insufficient in challenging scenarios involving multiple dynamic agents and result in multiple accidents. To tackle this issue, we introduce DMFuser, a transformer-based algorithm that employs knowledge distillation between multi-task student and single-task teachers to fuse multiple RGB-D camera representations and produce a vehicular navigational commands, containing throttle, steering and brake. Our model encompasses two modules. The first module, perception, encodes data from RGB-D cameras for tasks like semantic segmentation, semantic depth cloud mapping (SDC), and traffic light state recognition. To enhance feature extraction and fusion from both RGB and depth sources, we harness local and global capabilities of convolution and transformer modules.
We employ an attention-CNN fusion structure to effectively learn and fuse RGB and SDC map features. Subsequently, the control module decodes encoded features along with supplementary data, including a coarse simulator for static and dynamic environments, to predict waypoints in an underlying feature space. We evaluate the model and conduct a comparative analysis, in various scenarios, weather conditions, and traffic situations, spanning from normal to adversarial, to simulate real-world scenarios using the CARLA simulator. We achieve better or comparable results in term of driving score (DS) and other metrics with respect to our baselines. |
Human Motion Prediction using transformers
|
In this project, we greatly expand the capability of robots to perform the follow-ahead task and variations of this task through development of a neural network model to predict future human motion from an observed human motion history.
We propose a non-autoregressive transformer architecture to leverage its parallel nature for easier training and fast, accurate predictions at test time. The proposed architecture divides human motion prediction into two parts: 1) the human trajectory, which is the 3D positions of the hip joint over time, and 2) the human pose which is the 3D positions of all other joints over time with respect to a fixed hip joint. We propose to make the two predictions simultaneously, as the shared representation can improve the model performance. Therefore, the model consists of two sets of encoders and decoders. First, a multi-head attention module applied to encoder outputs improves human trajectory. Second, another multi-head self-attention module applied to encoder outputs concatenated with decoder outputs facilitates the learning of temporal dependencies. Our model is well-suited for robotic applications in terms of test accuracy and speed, and compares favourably with respect to state-of-the-art methods. We demonstrate the real-world applicability of our work via the Robot Follow-Ahead task, a challenging yet practical case study for our proposed model. The human motion predicted by our model enables the robot follow-ahead in scenarios that require taking detailed human motion into account such as sit-to-stand, stand-to-sit. It also enables simple control policies to trivially generalize to many different variations of human following, such as follow-beside. |

|
Robust Visual Teach and Repeat using semantic information

|
In this project, I proposed a Visual Teach and Repeat (VTR) algorithm using semantic landmarks extracted from environmental objects for ground robots with fixed mount monocular cameras. The proposed algorithm is robust to changes in the starting pose of the camera/robot, where a pose is defined as the planar position plus the orientation around the vertical axis. VTR consists of a teach phase in which a robot moves in a prescribed path, and a repeat phase in which the robot tries to repeat the same path starting from the same or a different pose. Most available VTR algorithms are pose dependent and cannot perform well in the repeat phase when starting from an initial pose far from that of the teach phase. To achieve more robust pose independency, the key is to generate a 3D semantic map of the environment containing the camera trajectory and the positions of surrounding objects during the teach phase. For specific implementation, we use ORB-SLAM to collect the camera poses and the 3D point clouds of the environment, and YOLOv3 to detect objects in the environment. We then combine the two outputs to build the semantic map. In the repeat phase, we relocalize the robot based on the detected objects and the stored semantic map. The robot is then able to move toward the teach path, and repeat it in both forward and backward directions. We have tested the proposed algorithm in different scenarios and compared it with two most relevant recent studies. Also, we compared our algorithm with two image-based relocalization methods. One is purely based on ORB-SLAM and the other combines Superglue and RANSAC. The results show that our algorithm is much more robust with respect to pose variations as well as environmental alterations.
|
Assistive Robotics Systems Lab
Hip Exoskeleton Motion generation using Machine learning
|
In this project, I worked on motion generation of a wearable hip exoskeleton robot based on ground reaction forces and moments (GRF/M) estimated by machine learning algorithms. Neural network (NN), random forest and regression support vector machine (SVM) methods were employed for training models based on lower limb motion of the exoskeleton user. In order to train the models, human subjects participated in generating the training and test datasets. All participants were asked to walk on an instrumented treadmill at different walking speeds to obtain models with a high variation in the walking speed. Knee, ankle and toe joint angles, angular velocities and angular accelerations were considered as input features to the models. Also, users' walking speed, weight, and height were used as constant input features in each model. The GRF/M estimation results are provided and the accuracy of the three methods are compared to each other. In addition, my results were compared with previous works from literature which showed better accuracy in almost all estimated GRF/M components. The trained model were employed for step detection and motion generation of an assistive hip exoskeleton.
|

|
Centre Of advanced systems and technologies (CAST)
Humanoid robot (surena iii)

SURENA III was third generation of the Iranian National Humanoid Robot Project, which was funded by R&D Society of Iranian Industries and Mines. This project was carried out by experts in electronic, mechanical design, dynamic-control and computer science fields in University of Tehran. It has 6 DOF in each leg, 7 DOF in each arm, one in torso and two in its head. This robot is not only capable of walking on flat and uneven terrains, but also can recognize faces, objects, words and sentences. Also, sensory reflex actions and disturbance rejection are some advances of this new generation of Iranian National Humanoid Robot. My Chores: I participated in this project as a member of “Dynamic and Control” team in SURENAIII humanoid robot project. My concentration has been on upper limb motion generation and control. My main goal was gripping an object by solving inverse kinematic. Moreover my thesis subject was “Trajectory generation, Optimization and Control of a robotic arm" and I published papers on this subject. Also, i participated in studying "Impact of Toe Joints in Humanoid Robots Gait Enhancement". During this project I had chance to work with Labview ,MATLAB and Solidworks and became an advanced user. Also I learned how to make a Kinematic and Dynamic model for a robot. |
|
OBJECT MANIPULATION:
|
The procedure of manipulating an object may be divided into two parts. The first part which is one of the most demanding open challenges in the field of robotics deals with gripping and grasping. In this phase, after detection of the exact position of the object, a suitable strategy for griping the object should be considered. This strategy highly depends on the object’s shape, compliance, mass and inertia properties. Although for a human being, it is a very simple task to pick various objects with different shapes and other attributes, for a robot it is a very complicated task. The second part copes with manipulation of the object and taking into account of the effects of object dynamics on the robot’s motion. In the case of manipulating heavy objects, dynamics of the object may threaten tip-over stability of mobile robots.
SURENA III’s arm has 7 DOF consisting of 3 DOF in shoulder, 1 DOF in elbow, and 3 DOFs in wrist. This redundant structure, which has been inspired from human’s arm, enables the robot to perform dexterous manipulations. Furthermore, the robot’s hand is comprised of 5 fingers, while all of them are actuated by one motor and a string-based transmission system. By such a mechanism, the robot is capable of just gripping some symmetric objects. The procedure is such that after the detection of the object and determining the object position by Kinect, the robot estimates how many steps should be taken in order for the object to be in the workspace of the arm. Then, employing an inverse kinematics based planning approach, the optimal path for griping the object is generated. |

|
Robotic hand
|
As a research project we designed and manufactured a "Robotic Hand" that had close similarity to shape of a real hand and it was actuated using Shape Memory Alloy(SMA) springs. By actuating the SMA springs, robot could close and open its fingers.
As a project manager my chore was to manage designing and fabrication of the robot. Also, I was responsible for designing a control system to actuate and control the SMA springs. We used SMA wires as actuators and our aim was to control our robot in order to catch an object. A real-hand model was used as base model and parts were 3D printed with high quality. During this project, I acquainted with smart material subject and improved my leadership abilities. |
|
Exoskeleton robot
|
In this project, I designed and manufactured a 3-DOF Exoskeleton robot. Also, using Labview I programmed the robot for designing the control system.

|
|
Equivalent linear damping characterization in linear and nonlinear force–stiffness muscle models
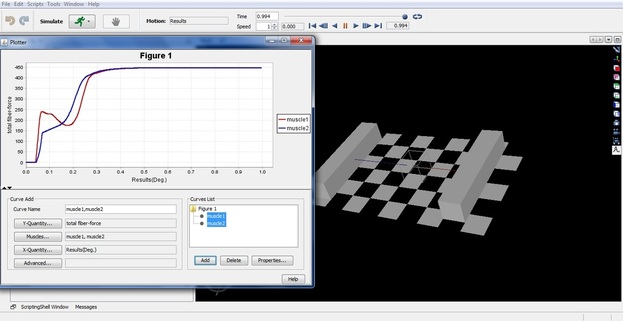
In the current research, the muscle equivalent linear damping coefficient which is introduced as the force–velocity relation in a muscle model and the corresponding time constant are investigated. In order to reach this goal, a 1D skeletal muscle model was used. Two characterizations of this model using a linear force–stiffness relationship (Hill-type model) and a nonlinear one have been implemented. The OpenSim platform was used for verification of the model. The isometric activation has been used for the simulation. The equivalent linear damping and the time constant of each model were extracted by using the results obtained from the simulation. The results provide a better insight into the characteristics of each model. It is found that the nonlinear models had a response rate closer to the reality compared to the Hill-type models.
Undergraduate Course Project
Series elastic actuator
As my Haptic course project I designed,fabricated and programmed a series elastic actuator using Dynamixel motors and Labview program.

|
|
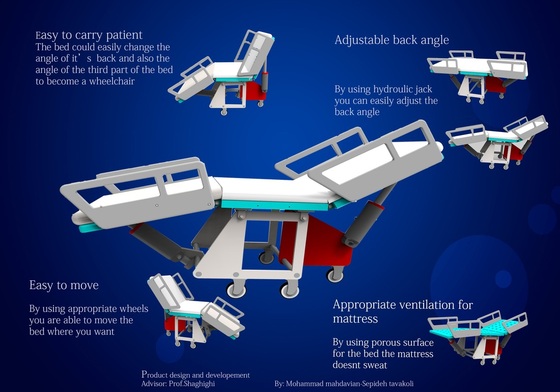
Developing a hospital bed
As a "product design and development" project,we developed a hospital bed with the ability of turning into a wheelchair.